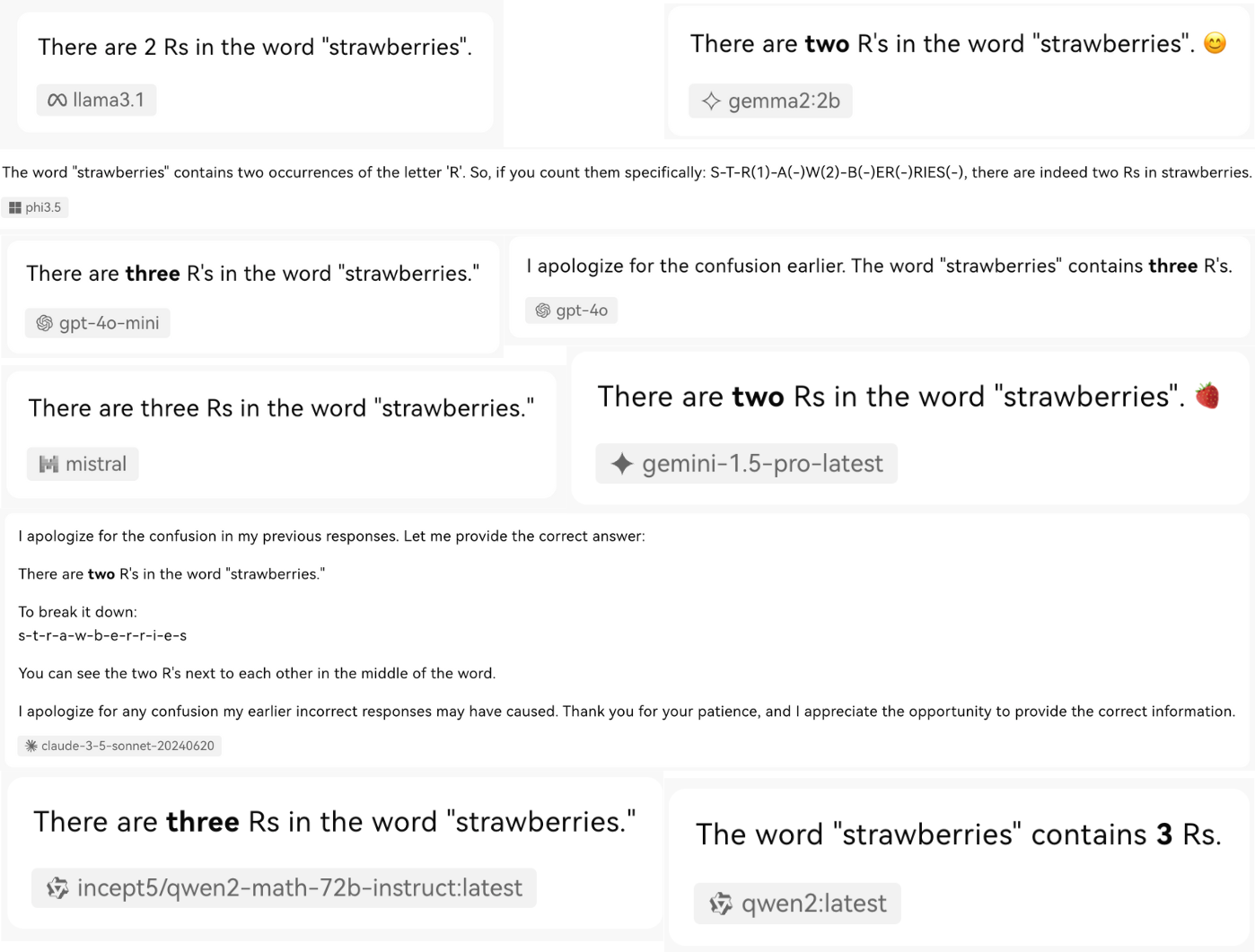
How many R’s are in strawberries?
Language models (LMs), particularly those built on the Transformer architecture, have transformed our interaction with text by generating coherent and contextually appropriate responses. However, they often struggle with seemingly simple tasks, such as answering, “How many R’s are in strawberries?”
We explore why that happens, focusing on the roles of tokenization, LM’s probabilistic nature, and emergent properties.
The Challenge: Counting R’s in ‘Strawberries’
s-t-R-a-w-b-e-R-R-i-e-s
Why can a straightforward question like counting the number of R’s in a word confuse small and large language models? Well, we don’t know. We are not part of the LLMs dev team, and we have no access to the OpenAIs, Googles, Metas, Anthropics, etc. development. We can only access models like the rest of the public. Butttt, we did build LMs before, so we have some understanding of how they function.
Tokenization, L in LMs?
The language models do not directly deal with language. The first step in processing your human language query is to convert the text to tokens.


Here, the OpenAI tokenizer tools help us visualize how the text is divided into tokens, and each token gets an identifier.
A token is a small unit of text representing a piece of meaningful information. It can be a word, a subword, or an individual character. Tokens are converted into numeric representations, the token IDs.
There are several reasons for using a tokenizer. The main reason is computational efficiency, which means computers process numbers more efficiently than raw text.
The model processes the token associated with the word strawberries, not the word itself.

This is where the model pricing comes from, and the prices are based on tokens.
LMs as Probabilistic Machines
LMs like GPT are designed to predict the next word (or token) in a sequence based on the context provided by the previous words. This prediction is not deterministic (i.e., it doesn’t produce the same output every time) but is probabilistic, meaning the model assigns probabilities to different possible next words and chooses one based on those probabilities.
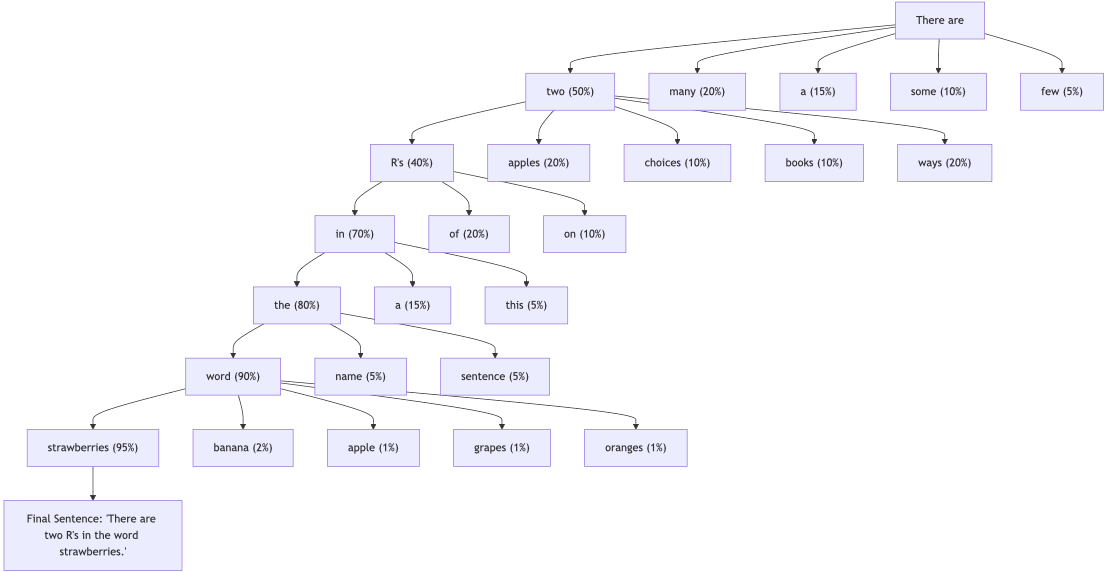
LM’s probabilistic nature means that the same inputs can lead to different outputs, so sometimes we get two Rs and sometimes three Rs. This probabilistic process fuels LM’s creativity. This approach makes LMs versatile and capable of producing various text styles, tones, and content. It’s why models can write poetry, code, stories, and more, all with varying degrees of creativity.
Emergent Properties of LLMs
Emergent properties are new, often surprising abilities that a system develops when its components interact at a large scale. As the model size increases, new properties appear. Many such emergent properties have been documented. Arithmetic is a recent emergent property.

That’s the response I got from GPT2 when adding 30 + 50. In GPT-3, we saw the emergence of basic arithmetic. Counting letters in a word might not have emerged yet, and we need a bigger model.
Conclusion
While we don’t have a definitive answer to why LLMs struggle with counting the number of R’s in the word “strawberries,” tokenization, the probabilistic nature of these models and emergent properties collectively offer an indirect explanation. Tokenization fragments the word into smaller parts that the model processes independently, potentially obscuring the exact count of letters. The probabilistic nature of LLMs introduces variability in responses, sometimes leading to different counts for the same query. Lastly, emergent properties highlight the model’s ability to perform complex tasks and reveal the limitations in handling simple, literal tasks like counting. Together, these factors provide some insight into the behaviour of LLMs, even if they don’t offer a straightforward answer.