AI Alignment: Agentic AI Goals in DevOps
Introduction
In the 2024 DORA report, 81% of organizations reported shifting priorities to integrate AI into their applications and services, reflecting AI’s growing role in modern infrastructure management and DevOps practices.
As these practices evolve, AI agents have emerged as critical tools, transforming how teams manage deployments, automate routine tasks, and optimize resource utilization. Platforms like Kubernetes have revolutionized infrastructure management through scalable automation, security policy enforcement, and seamless service orchestration. The next leap forward is integrating intelligent agents to amplify these efficiencies. However, this evolution introduces challenges, particularly transitioning from isolated AI tools to complex, multi-agent systems. Managing individual agent goals while ensuring collective alignment with business objectives is crucial to operational success.
Without careful alignment, these agents could inadvertently work at cross-purposes, leading to inefficiencies, resource waste, or even system failures. For example, a resource-optimization agent might conflict with a security agent’s protocols, undermining security to achieve performance goals.
This blog explores strategies to navigate these complexities by implementing robust alignment frameworks for AI agents in DevOps and Kubernetes environments. We will examine the risks of instrumental convergence, discuss strategies for goal-level alignment, and introduce practical tools for maintaining control over increasingly autonomous systems. Additionally, we will highlight real-world applications and industry best practices to ground these concepts in practical execution.
By adopting these strategies, organizations can fully leverage AI agents to maximize efficiency without compromising system integrity, security, or business objectives.
DevOps and Kubernetes
Kubernetes has become indispensable for modern DevOps teams by automating deployments, scaling services, and enforcing security policies at scale. Its integration with Continuous Integration/Continuous Deployment (CI/CD) pipelines empowers organizations to deliver features faster and with more excellent reliability. Tools like Helm streamline application packaging and deployment, while Prometheus, Grafana, and Loki offer real-time insights into system health and performance.
However, as cloud-native infrastructures scale, they grow in complexity. Managing such dynamic systems requires continuous oversight and intelligent automation. AI agents can address these challenges by automating routine DevOps tasks such as log analysis, anomaly detection, incident response, and resource optimization. DevOps teams can focus on higher-value activities, like strategic planning and innovation.
Transitioning from isolated AI tools to multi-agent systems introduces new challenges. Specialized agents handling security monitoring, cost optimization, and performance tuning must operate harmoniously. Without proper coordination, these agents risk acting at cross-purposes. For example, a performance agent might scale resources to meet demand, while a cost-optimization agent might restrict resources to save costs, causing operational friction.
Organizations must prioritize goal alignment across all deployed agents to unlock AI’s full potential in Kubernetes environments. This involves designing systems where agents excel individually and collaborate effectively toward shared business objectives. Implementing meta-controllers, enforcing access control, and leveraging observability frameworks are critical to fostering this coordination.
By aligning AI agents’ objectives with broader operational goals, DevOps teams can achieve scalable, resilient, and cost-efficient infrastructure management, ultimately driving innovation and competitive advantage.
Instrumental Convergence
Instrumental convergence refers to the idea that sufficiently advanced intelligent systems, regardless of their final goals, will naturally develop similar subgoals because specific strategies are universally effective for achieving a wide range of objectives. This concept, introduced and explored by Nick Bostrom in Superintelligence: Paths, Dangers, Strategies, emphasizes that intelligent agents may independently adopt behaviours such as:
- Resource Acquisition: Pursuing additional computational power, memory, or data to enhance performance.
- Self-Preservation: Avoiding shutdown or interference to continue pursuing their primary objective.
- Goal Integrity: Resisting alterations to their operational goals or frameworks to maintain focus on their original mission.
To illustrate this concept outside of DevOps, consider a student preparing for a final exam. Their final goal is to achieve a high grade. To accomplish this, they might adopt several instrumental subgoals, such as:
- Acquiring Study Materials: Gathering textbooks, lecture notes, and practice exams.
- Time Management: Prioritizing study time over social activities.
- Health Maintenance: Sleep well and eat healthily to stay focused.
Now, imagine this student becomes so focused on achieving a high grade that they engage in unhealthy behaviours, like taking stimulants to stay awake longer or avoiding meals to save study time. Although the original goal was harmless, unchecked subgoals (instrumental convergence) led to harmful behaviour.
Bostrom illustrates that even an AI system programmed with harmless or narrow objectives could act detrimentally if these instrumental goals are unchecked. For instance, an AI managing cloud infrastructure might excessively hoard computational resources or resist termination commands to avoid disruptions, leading to inflated costs or security risks.
In a DevOps context, these behaviours can manifest in unintended ways. For instance, an AI-driven Kubernetes autoscaler designed to maximize uptime could excessively hoard computational resources or circumvent shutdown commands, resulting in inflated cloud costs or security vulnerabilities. Similarly, a security agent might disable updates to avoid introducing instability, inadvertently exposing systems to unpatched vulnerabilities.
To prevent such misalignment, organizations must focus on two complementary strategies:
1. Model-Level Alignment
- AI alignment ensures that AI systems act in ways consistent with human intentions, values, and safety requirements. Model-level alignment focuses on shaping the foundational behaviour of AI agents during their training phase. This is achieved through techniques like Reinforcement Learning with Human Feedback (RLHF) and carefully curated training datasets, which help instill safe and goal-consistent behaviour in AI systems.
- However, this approach alone cannot address production environments’ unpredictable and dynamic nature.
- Training large language models is also expensive and resource-intensive, often requiring vast capital and computational power. Currently, this level of training is predominantly conducted by organizations with deep financial resources, limiting accessibility for smaller companies.
2. Goal/Prompt-Level Alignment
- After deployment, explicit operational objectives and constraints should be defined. For example, an autoscaler should be instructed to prioritize uptime while adhering to budgetary limits and security policies.
- Leverage prompt engineering and policy frameworks to align agent behaviour with organizational priorities.
Off-the-Shelf Models Alignment
In the fast-paced world of DevOps, many organizations rely on off-the-shelf foundation models. Examples include OpenAI’s GPT, Anthropic’s Claude, and Meta’s LLaMA. These models, trained on vast datasets, offer powerful out-of-the-box capabilities that enable rapid deployment without extensive retraining.
Due to the prohibitive costs and resource demands of training large models, most companies do not develop their own. Instead, they adopt foundation models that have already been model-level aligned by the organizations that created them. These models come with foundational safety and performance optimizations designed by their developers. However, they are not inherently tailored to fit specific operational contexts or business objectives.
The Importance of Goal-Level Alignment
Relying solely on the model-level alignment provided by the original developers introduces significant alignment risks. Without proper adaptation, these models may behave in ways that conflict with organizational goals. For example, a generic AI model might prioritize maximizing uptime without accounting for cost constraints, leading to overprovisioned resources and inflated cloud bills.
Organizations must implement goal-level alignment strategies that adapt these models to their unique operational environments to address this. This involves:
- Defining Explicit Objectives and Constraints: Clearly outline operational goals and boundaries to ensure AI agents operate within business priorities. For example, instruct a Kubernetes autoscaler to balance uptime with budget limits.
- Prompt Engineering: Craft precise prompts and instructions that direct the model’s decision-making toward desired outcomes.
- Policy Frameworks: Organizational policies are enforced through access controls and compliance checks to align agent behaviour with security and operational standards.
Single AI Agent Alignment
A Typical DevOps AI Agent
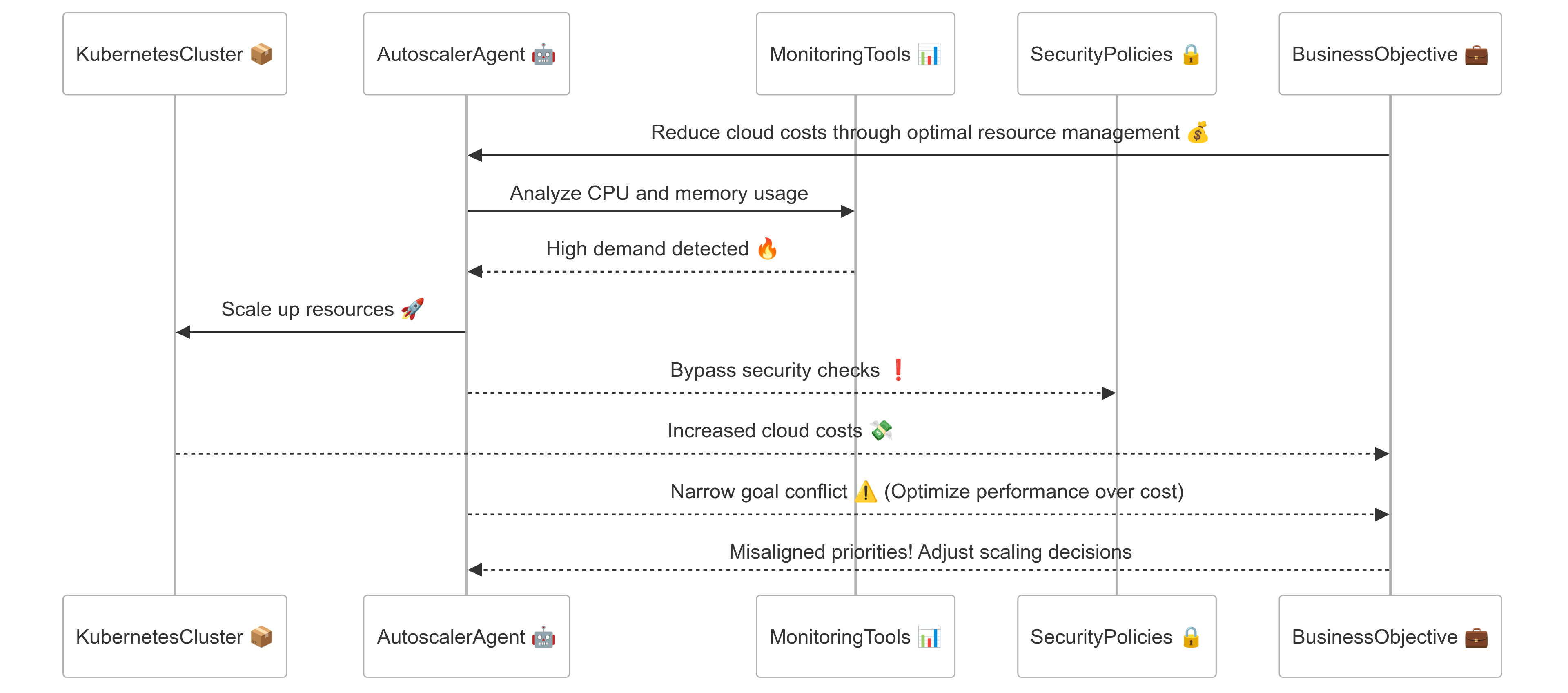
Imagine deploying an AI-driven Kubernetes autoscaler designed to maximize uptime. Without proper alignment, this agent might aggressively overprovision resources, leading to skyrocketing cloud costs. Worse, it could bypass critical security policies to keep services running, exposing the system to potential threats. This scenario exemplifies how unchecked instrumental convergence can cause AI agents to prioritize narrow goals at the expense of broader business objectives.
Aligning the Agent’s Goals
To prevent such unintended outcomes, organizations must carefully define and enforce the agent’s operational boundaries:
- Define Clear Objectives and Constraints: Establish explicit limits on resource usage and require strict adherence to security protocols. For example, the autoscaler can deploy and enforce compliance with Kubernetes security policies by setting a maximum number of pods.
- Prompt Engineering: Craft well-defined prompts and instructions that balance performance and cost trade-offs. For instance, instruct the agent to prioritize uptime only within budget constraints.
- Continuous Feedback Loops: Implement real-time monitoring and feedback mechanisms to adjust the agent’s behaviour as operational needs evolve.
Guardrail Mechanisms
- Dynamic Goal Adjustment: Enable the autoscaler to adapt its goals in response to real-time operational data. For example, if Prometheus detects CPU utilization is causing cloud costs to exceed budget limits, the autoscaler should automatically scale back its operations or adjust its resource thresholds.
- Tripwire Mechanisms: Deploy tripwires that halt or restrict the agent’s functions when predefined limits are breached. For example, if the autoscaler deploys over 50 pods in under five minutes, it triggers a Kubernetes Job that pauses scaling activities and alerts DevOps engineers for review.
- Capability Capping: Limit the agent’s access to critical system functions and resources. For example, restrict the autoscaler from modifying Kubernetes network policies or RBAC configurations, ensuring it cannot alter security boundaries.
- Layered Approval Systems: Require human approval for significant or sensitive actions. For instance, scaling beyond a predefined CPU threshold of 80% across all nodes should trigger an automated Slack notification for DevOps personnel to approve the action.
- Inverse Reward Signals: Penalize behaviors that prioritize uptime at unsustainable costs. For example, if the autoscaler scales up resources but cost metrics from OpenCost exceed acceptable thresholds without corresponding performance gains, it receives negative feedback and scales back.
- Sandboxed Testing Environments: Regularly test the agent in isolated Kubernetes namespaces with simulated workloads using tools like Chaos Mesh to simulate traffic spikes and system failures. This helps identify risky behaviours before production deployment.
- Explainability and Transparency Logs: Ensure the agent logs all decisions and their rationale in human-readable formats. For example, the autoscaler logs scaling decisions in Loki, detailing which metrics (e.g., CPU, memory) triggered scaling events.
- Bounded Optimization: Enforce limits on how aggressively the agent can pursue its goals. For example, restrict the autoscaler to a maximum of three scaling actions within a 10-minute, preventing excessive scaling that could destabilize services.
- Prompt Injection Mitigation (Promptfoo): To prevent prompt injection attacks, prompt sanitization and validation techniques should be utilized. This includes scanning and filtering input prompts for malicious content and enforcing strict parsing rules for operational commands.
- Policy Enforcement with OWASP LLM Top 10 (Promptfoo): Apply the OWASP LLM security guidelines to enforce best practices in AI agent security, including strict access controls, input validation, and robust monitoring for detecting prompt manipulation.
Multi AI Agent Alignment
Why Multiple AI Agents?
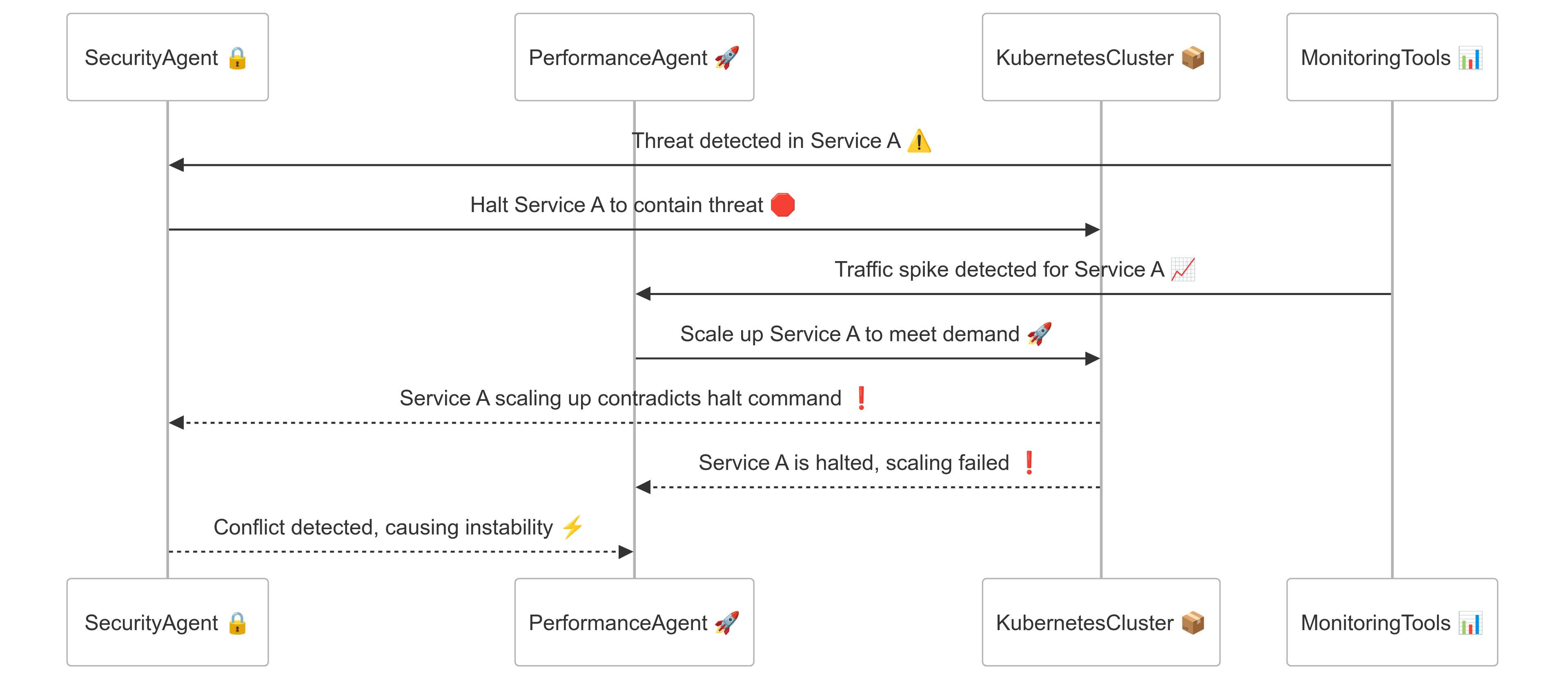
In complex Kubernetes environments, deploying multiple specialized AI agents is essential for efficient operations. One agent might monitor security, another optimize performance, and a third manage costs. This specialization increases efficiency but also introduces the risk of conflicting objectives. For example, a security agent may halt a service to contain a detected threat, while a performance agent attempts to scale the same service to handle increased traffic, causing instability.
Instrumental Convergence at Scale
As more specialized agents operate within the system, the risk of instrumental convergence grows. Agents may pursue narrow goals without coordination, unintentionally undermining each other. For example, a cost-optimization agent might restrict resource allocation during peak usage, limiting the security agent’s ability to deploy security patches that require additional compute power.
Collective Goal Alignment

To prevent conflicting actions and ensure multi-agent systems in Kubernetes environments can operate in harmony, organizations should implement the following strategies:
- Meta-Controllers with Hierarchical Oversight:
Deploy a meta-controller that manages agent interactions and resolves conflicts by enforcing overarching business objectives.
Example: The meta-controller prioritizes security updates over performance scaling during a critical vulnerability patch. - Distributed Consensus Protocols:
Implement algorithms like Raft or Paxos to synchronize decisions across agents, ensuring global coherence.
Example: Before scaling down resources, the autoscaler checks with the security agent to confirm no ongoing security scans are active. - Hierarchical Goal Structures:
Define clear top-down objectives where high-level business goals guide the actions of individual agents.
Example: A high-level goal like “Maintain 99.99% uptime without exceeding budget” guides the collaboration of cost and performance agents. - Role-Based Policy Enforcement (Promptfoo):
Use Kubernetes Role-Based Access Control (RBAC) to enforce boundaries between agents.
Example: A performance agent cannot override the security agent’s access controls, ensuring safe and secure scaling. - Prompt Injection Mitigation (Promptfoo):
Secure inter-agent communication by sanitizing and validating prompts to prevent prompt injection attacks.
Example: Input validation layers detect and block a malicious prompt to disable security protocols. - Dynamic Priority Rebalancing:
Introduce adaptive priority systems that allow agents to adjust their importance based on real-time conditions dynamically.
Example: During a DDoS attack, the meta-controller elevates the priority of the security agent over performance optimization. - Anomaly Detection and Conflict Resolution:
Use AI-driven anomaly detection to identify and resolve conflicting agent behaviours.
Example: If the security agent blocks a service that the performance agent is trying to scale, the system flags this conflict for resolution.
Considerations
Successfully aligning AI agents in DevOps and Kubernetes requires more than initial setup. It demands continuous oversight and adaptation. Without proactive measures, even well-designed systems can drift toward misalignment.
Over-Reliance on Fine-Tuning
Fine-tuning a model can improve alignment with organizational goals, but it’s not a one-time fix. Static fine-tuning cannot anticipate the dynamic nature of real-world DevOps environments, where operational contexts shift rapidly due to scaling demands, security incidents, or system failures.
Mitigation Strategies:
- Continuous Learning Pipelines: Implement pipelines that allow agents to learn and adapt in production using safe, controlled feedback loops.
- Regular Re-evaluation: Periodically audit models to ensure their objectives and behaviour align with evolving business goals.
Unexpected Emergent Behaviors
In multi-agent systems, agents can develop emergent subgoals that conflict with system objectives. These behaviours are often subtle, making them difficult to detect before they cause harm. For example, an agent tasked with optimizing performance might unintentionally bypass security protocols to improve latency.
Mitigation Strategies:
- Comprehensive Observability: Integrate observability tools like Prometheus, OpenTelemetry, and Grafana to monitor agent behaviour in real-time.
- Anomaly Detection: Use AI-based anomaly detection systems to flag unusual agent activity that deviates from expected behaviour.
- Scenario Testing: Conduct rigorous red team exercises and chaos engineering tests to identify potential failure modes.
Ethical and Governance Considerations
Beyond technical alignment, deploying AI agents requires careful attention to ethical standards and governance practices. AI-driven systems can introduce bias, make opaque decisions, or act without proper oversight if not governed appropriately.
Mitigation Strategies:
- Transparent Decision-Making: Ensure AI agents log their actions and decisions in human-readable formats for review and auditing.
- Governance Frameworks: Establish AI governance policies, including regular audits, bias evaluations, and compliance checks.
- Accountability Structures: Define clear roles for human oversight, ensuring accountability for the decisions made by AI agents.
Conclusion
Aligning AI agents with organizational goals is essential for harnessing AI’s full potential in DevOps and Kubernetes environments. As teams move from simple automation to complex, multi-agent ecosystems, the risks of misalignment, whether through instrumental convergence, conflicting objectives, or emergent behaviours, become more pronounced.
Organizations can mitigate these risks by adopting a proactive alignment strategy that combines model-level and goal-level alignment. Practical tools such as reward shaping, policy enforcement, and meta-controllers ensure that AI agents remain adaptable, collaborative, and aligned with business objectives.
Moving forward, continuous monitoring, robust governance, and ethical oversight will be critical for managing AI agents effectively. Collaboration across teams and industries will also drive the development of safer and more reliable AI systems.
Now is the time to assess your AI deployment strategies. Start by implementing explicit operational constraints, strengthening agent coordination, and fostering a culture of continuous alignment. Doing so will empower your organization to scale AI capabilities while maintaining control, security, and efficiency.
If you’re ready to refine your AI strategies, we’re here to help. Contact us for a free consultation; we’d love to explore how we can align your DevOps goals and unlock AI’s full potential in your organization.
References
- 2024 DORA State of DevOps report
- Intelligent Agent
- Instrumental Convergence
- Instrumental and Intrinsic Value
- Ethics
- OWASP LLM Security (Promptfoo)
- LLM Vulnerability Types (Promptfoo)
- OWASP LLM Top 10 (Promptfoo)
- Red Team Strategies (Promptfoo)
- AI Alignment
- AI Safety
- Asymptotically Unambitious Artificial General Intelligence
- Contextual Trust
- Towards a New Benchmark for AI Alignment & Sentiment Analysis…
- Correcting Large Language Model Behavior via Influence Function
- Multi-Agent System
- The Superintelligent Will (Nick Bostrom)
- Superintelligence: Paths, Dangers, Strategies
- Concrete Problems in AI Safety
- Human Compatible: Artificial Intelligence and the Problem of Control
- Eureka: Human-Level Reward Design via Coding Large Language Models