AI That Thinks Like a Human: Titans & Transformer² and the Future of Adaptive Intelligence
Titans and Transformer-Squared Introduction
Artificial intelligence (AI) has experienced a seismic shift over the past decade, moving from generic, one-size-fits-all models to architectures capable of mastering specialized skills and tasks. This evolution reflects a broader push toward intelligent, adaptable, and efficient AI, key traits required to tackle real-world applications’ complex, ever-changing challenges.
While traditional transformer-based models have revolutionized natural language processing (NLP), their rigidity and monolithic design limit their effectiveness in dynamic, specialized fields. Despite their power, current AI systems face two critical challenges:
- Memory limitations: Forgetting past interactions beyond a fixed context window.
- Adaptability issues: Requiring costly retraining to specialize in new tasks.
These limitations become especially problematic in high-stakes environments like DevOps, where AI must continuously monitor, optimize, and react to evolving workflows, from Kubernetes deployments to CI/CD pipeline automation. A static AI model simply isn’t enough.
What if AI could think more like a human?
What if an AI could remember past optimizations, recall system failures, and adapt its strategies in real time without retraining?
Enter Titans and Transformer²
Titans and Transformer² (Transformer-Squared or Transformer 2.0) are groundbreaking AI architectures designed to address these challenges. Titans reimagine how AI models handle memory, introducing a memory system that mimics how humans balance short and long-term information. Meanwhile, Transformer² redefines adaptability by enabling AI to fine-tune itself on the fly, making it a powerhouse for mastering new skills in real-time.
These innovations go beyond theoretical breakthroughs. They unlock real-world applications across industries. Imagine an AI that seamlessly adapts to changing cloud infrastructure, proactively optimizing DevOps workflows like a seasoned engineer. The potential extends beyond DevOps, shaping the future of finance, healthcare, and intelligent automation.
This blog will explore how Titans and Transformer² surpass traditional transformers, their strengths, and how they can work together to enhance Agentic AI.
The Birth of Transformers
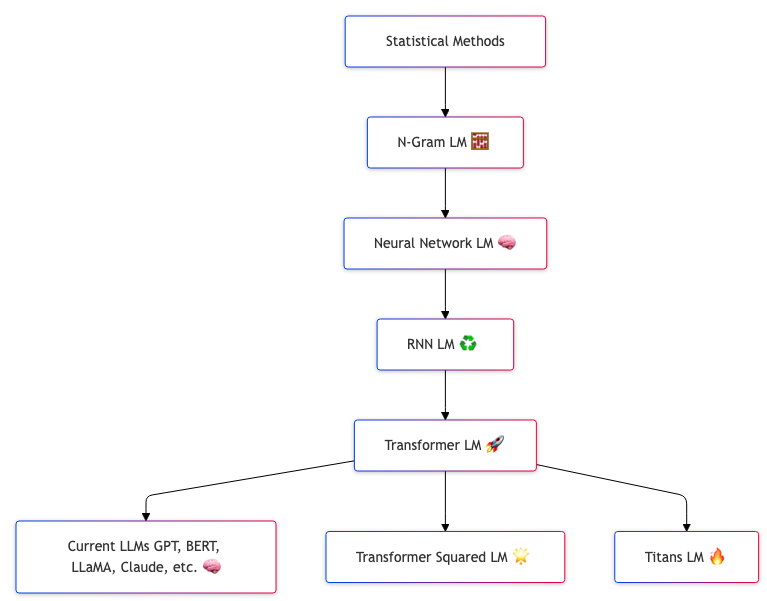
LMs over time
The release of the paper Attention Is All You Need in 2017 was a defining moment in the history of AI. It introduced transformer architecture, a groundbreaking model that revolutionized sequence-to-sequence tasks such as translation, summarization, and language modelling. Before transformers, Recurrent Neural Networks (RNNs) and their variants, like Long Short-Term Memory (LSTM) networks, dominated the landscape. However, these models faced limitations, such as sequential computation, which hampered scalability and parallelization.
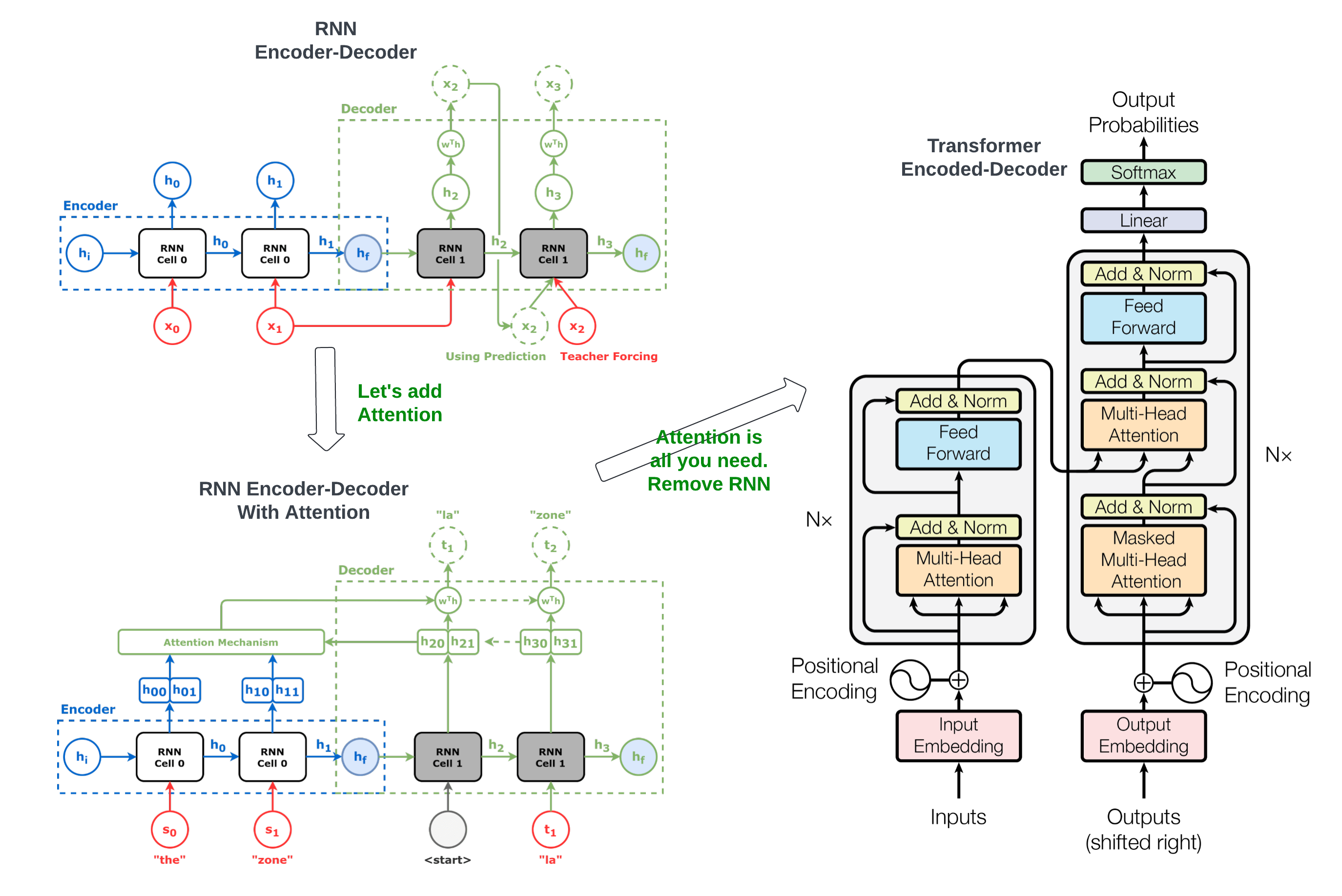
The transformer architecture departed from this paradigm by leveraging a novel concept of self-attention. This mechanism allows models to process all input tokens simultaneously while attending to specific input parts as needed. The attention mechanism enabled transformers to handle longer data dependencies and significantly improved computational efficiency. In practical terms, transformers could process entire sentences, paragraphs, or documents rather than token-by-token, making them much faster than RNNs and LSTMs.
Features of Transformers
- Self-Attention Mechanism: The self-attention mechanism is the core of the transformer. It computes the relationships between every token in a sequence, enabling the model to capture local and global dependencies. Transformers utilize attention mechanisms that simultaneously attend to the entire sequence context. RNNs compress information into a hidden state, limiting the context they can remember effectively.
- Multi-Head Attention: The transformer employs multiple attention heads to enhance further its ability to capture complex patterns. Each head operates on a different subspace of the input data, allowing the model to focus on various aspects of the input simultaneously.
- Positional Encoding: Since transformers lack the sequential structure of RNNs, they use positional encodings to provide information about the order of tokens in a sequence.
- Parallelization: The Transformer architecture allows for significant parallelization during training, as it does not rely on sequential computations like RNNs. RNNs process inputs sequentially, which limits their ability to utilize modern hardware efficiently, especially for longer sequences.
- Handling Long Sequences: Transformers can effectively manage long-range dependencies through self-attention mechanisms, which connect all positions in the input and output sequences without the sequential constraints faced by RNNs. In contrast, RNNs must traverse longer paths, which can make learning long-range dependencies difficult due to vanishing gradient issues.
Transformers quickly became the backbone of state-of-the-art models, including OpenAI’s GPT series, Google’s BERT, and Meta’s LLaMA. These models showcased the architecture’s transformative power, achieving breakthroughs in NLP tasks such as translation, text generation, and sentiment analysis. Transformers also demonstrated versatility, applied to areas beyond language, including image processing, speech recognition, and protein folding.
Challenges of Transformers
Despite their strengths, transformers have limitations. The quadratic computational complexity of the self-attention mechanism limits their ability to handle highly long sequences efficiently. As sequence length increases, the computational cost grows rapidly, making transformers less suitable for tasks requiring large context windows, such as processing lengthy legal documents or analyzing multi-year time series data.
Additionally, transformers’ static nature poses challenges for task-specific applications. Fine-tuning a large transformer for a particular task requires substantial computational resources and can lead to inefficiencies. This rigidity becomes a bottleneck in domains like DevOps, where the environment and requirements change dynamically.
These limitations paved the way for developing advanced architectures like Titans and Transformer², which address scalability, adaptability, and specialization head-on. By retaining the core strengths of the transformer while introducing innovations in memory and task-specific learning, these architectures mark the next step in AI’s evolution.
Titans

While the transformer architecture has been transformative, it struggles with long-term dependencies and scalability. Transformers operate within a limited context window, typically spanning a few thousand tokens. As tasks demand processing longer sequences, such as multi-step reasoning or real-time system monitoring, this limitation becomes a bottleneck. Enter Titans, a groundbreaking neural architecture designed to tackle these challenges by reimagining how models handle and store memory.
Titans’ innovation lies in its hybrid memory system, which integrates short-term and long-term memory. This system mimics how humans manage information, combining immediate focus with the ability to recall significant past events and retain overarching knowledge.
Titans Architecture
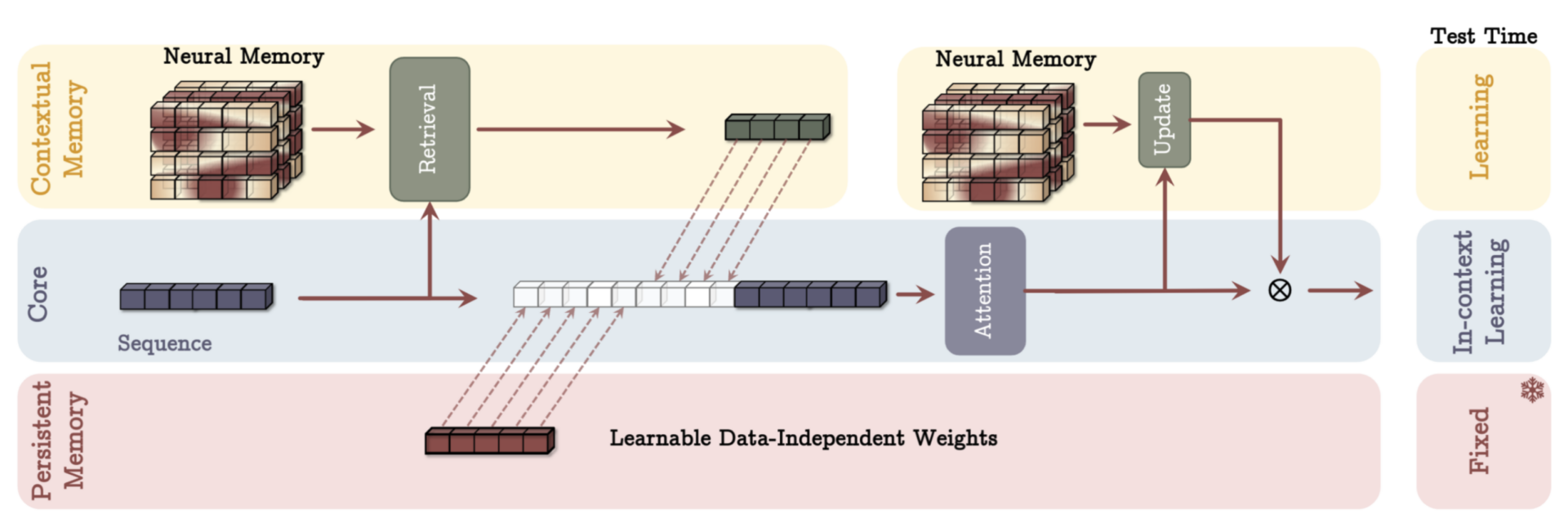
The Titans architecture is built upon the integration of contextual and persistent memory, two complementary systems that empower the model to handle complex, long-term tasks with precision and efficiency. These memory systems are implemented differently across the three Titan variants, Memory as Context (MAC), Memory as Gating (MAG), and Memory as a Layer (MAL), allowing for task-specific customization and optimization.
Short-Term Memory
Short-term memory in Titans functions like the working memory in your brain when solving a puzzle. It holds onto relevant information just long enough to complete a task. The attention mechanism is the short-term memory, which excels at modelling relationships within a fixed context window. This module focuses on the immediate input data, capturing local dependencies and patterns with high precision. However, like our brain’s short-term memory, it has limited capacity, making it ideal for tasks requiring a quick, precise understanding of recent information. The attention mechanism works by assigning weights to input tokens determining their relevance to each other in the current context. While incredibly effective for handling short-range dependencies, it struggles with long sequences. To address this, Titans complement short-term memory with contextual and persistent memory, enabling the model to balance the precision of immediate context processing with the scalability of long-term data retention.
Contextual (Long-Term) Memory
Contextual memory in the Titans model serves as the long-term memory component. It dynamically updates as new input data is processed, allowing the model to store and retrieve relevant information from earlier in a sequence. Encoding historical context into its parameters helps handle long-term dependencies beyond the fixed context window of attention mechanisms. Features like the surprise metric determine which data is important to remember or forget, enabling the model to scale efficiently to long sequences while retaining relevant information.
Contextual memory is like your brain’s ability to recall details from earlier book chapters while reading the current one. It keeps track of everything you’ve seen and updates as new information comes in. It connects essential dots and makes sense of the bigger picture, even if the story spans hundreds of pages. The Titans model remembers patterns from earlier parts of a task and uses that knowledge to understand what’s happening now.
Persistent Memory
Persistent memory in the Titans model is a set of input-independent, learnable parameters that encode task-specific knowledge. Unlike contextual memory, which updates dynamically, persistent memory remains fixed during training and inference. This memory provides a stable foundation of meta-knowledge about the task, helping the model maintain consistent reasoning and mitigate attention biases. It is often prepended to the input sequence as a static prefix, ensuring that foundational knowledge is always available during computation.
Persistent memory is the general knowledge you’ve studied before taking a test, such as knowing the grammar rules or basic math. It doesn’t change based on your question but gives you a solid foundation to approach any problem. In Titans, this type of memory stays fixed, providing consistent guidance to the model, ensuring it always remembers the “rules of the game,” no matter what data it’s working with.
DevOps automation: for example, an AI system managing Kubernetes clusters can store best practices for workload distribution, security policies, and anomaly detection, ensuring that decisions remain grounded in expert-level knowledge without requiring constant retraining.
| Feature | Short-Term Memory (Attention) | Contextual Memory (Long-Term) | Persistent Memory |
| Adaptability | Highly dynamic, changes with input | Dynamic, evolves with input | Static, does not change with input |
| Dependency | Input-dependent (local context) | Input-dependent (historical context) | Input-independent |
| Purpose | Process immediate, short-term context | Store historical, data-specific context | Provide general, task-specific knowledge |
| Nature | Focused on current input window | Flexible and temporal, spans sequences | Fixed and foundational |
| Scope | Limited to a fixed context window | Handles long-term dependencies across sequences | Global and task-wide knowledge |
Table: Comparing Model Memorie Types
Three Titan Variants
The Titans architecture introduces three main variants for incorporating memory into deep learning models. These variants differ in how they integrate short-term, long-term (contextual), and persistent memory, offering flexibility in balancing efficiency and effectiveness for various tasks.
Memory as a Context (MAC)
From references 3 – Memory as a Context
The MAC variant of the Titans architecture integrates three key branches: (1) Core, (2) Contextual (long-term) memory, and (3) Persistent memory. In this design, the core branch combines the long-term memory retrieved from earlier data and the fixed persistent memory with the input sequence. The combined sequence is then processed by the attention mechanism, which determines what parts of the information should be stored in long-term memory for future use.
At test time, the contextual memory parameters continue to adapt and learn from new inputs, enabling dynamic updates based on the current sequence. The core branch focuses on processing in-context information, while the persistent memory parameters remain fixed, acting as a stable source of task-specific knowledge that doesn’t change. This design allows MAC to balance short-term and long-term processing while maintaining a stable foundation of task knowledge. It is ideal for tasks requiring reasoning over historical and current data.
Memory as a Gate (MAG)
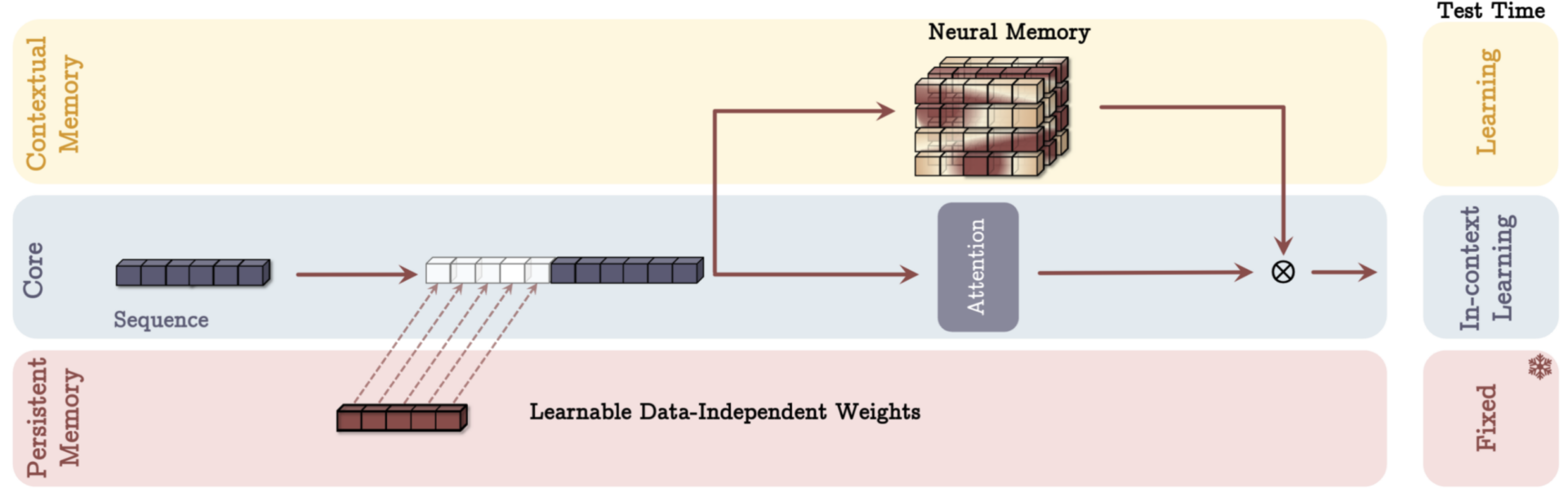
From references 3 – Memory as a Gate
The MAG variant of the Titans architecture also incorporates three branches: (1) Core, (2) Contextual memory (long-term), and (3) Persistent memory. However, unlike the MAC variant, MAG integrates only the persistent memory into the input sequence, while the contextual memory is processed separately. The outputs from the short-term (core branch) and long-term (contextual memory) modules are then combined using a gating mechanism, which dynamically determines the relevance of each memory source for the task at hand.
At test time, the behaviour mirrors that of MAC. The contextual memory parameters continue to learn and adapt based on the input sequence, while the persistent memory parameters remain fixed, providing stable, task-specific knowledge. The gating mechanism balances short-term and long-term memory, dynamically prioritizing the most helpful information for each specific input. This design makes MAG well-suited for tasks where the relative importance of short-term and long-term dependencies varies dynamically.
Memory as a Layer (MAL)
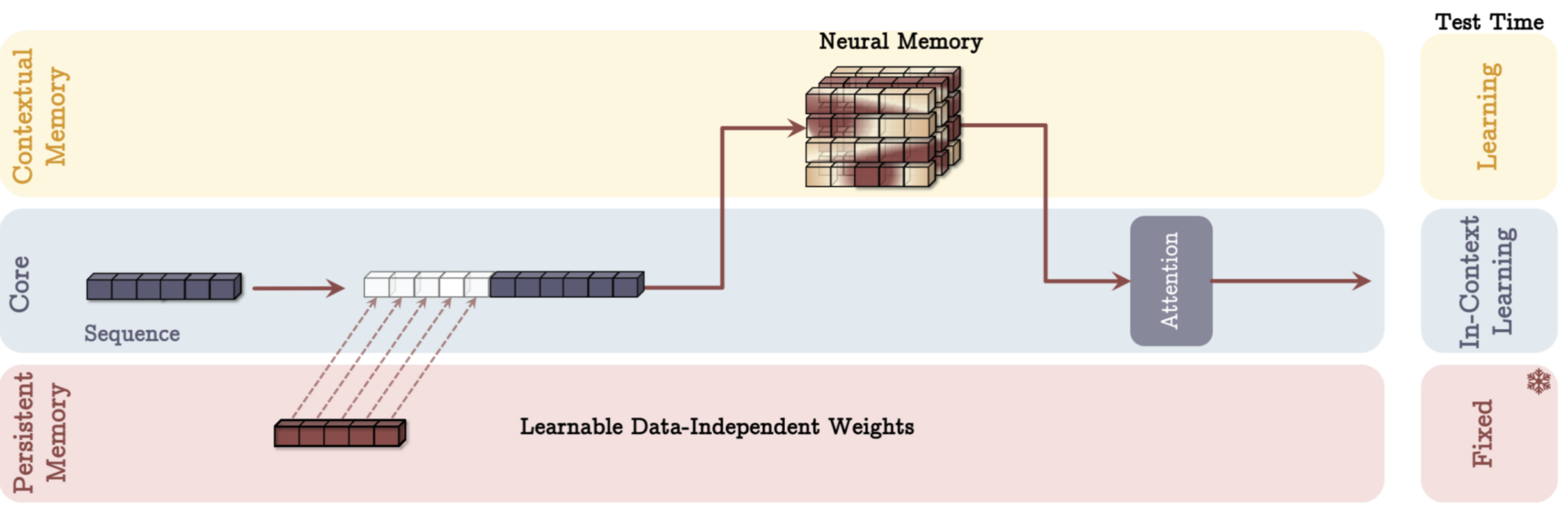
From references 3 – Memory as a Layer
The MAL variant of the Titans architecture integrates the memory system as a distinct layer within the model. In this design, the memory layer processes both the past (contextual memory) and the current context, compressing them into a more manageable representation before passing the output to the attention module. This preprocessing step allows the model to distill relevant information from long-term memory and current input, reducing the computational burden for the attention mechanism.
Unlike MAC and MAG, MAL’s memory and attention components operate sequentially, with memory acting as a preparatory step rather than being integrated directly into the attention process. This design simplifies the interaction between short-term and long-term memory but may limit the flexibility to leverage their complementary strengths dynamically. MAL is best suited for tasks where memory serves primarily as a preprocessing step, compressing information before detailed short-term attention processing.
Transformer²

While Titans solve the challenge of long-term memory retention, it does not address another critical issue: adaptability. Even with memory enhancements, AI models require expensive retraining to specialize in new tasks. This is where Transformer² takes over, introducing real-time, self-adaptive learning without retraining. Transformer² approach focuses on adaptability and task-specific optimization during inference. Transformer² represents the next stage in AI evolution, tackling one of the significant limitations of traditional transformer architectures: their static nature. Traditional fine-tuning methods for LLMs are resource-intensive and static, meaning they cannot efficiently adapt to new tasks or dynamic environments. Once trained, transformers typically require extensive fine-tuning to specialize in new tasks. Transformer² disrupts this paradigm by introducing dynamic self-adaptation. Self-adaptation allows models to fine-tune themselves in real-time without retraining, making them exceptionally versatile for specialized applications.
Transformer² Architecture
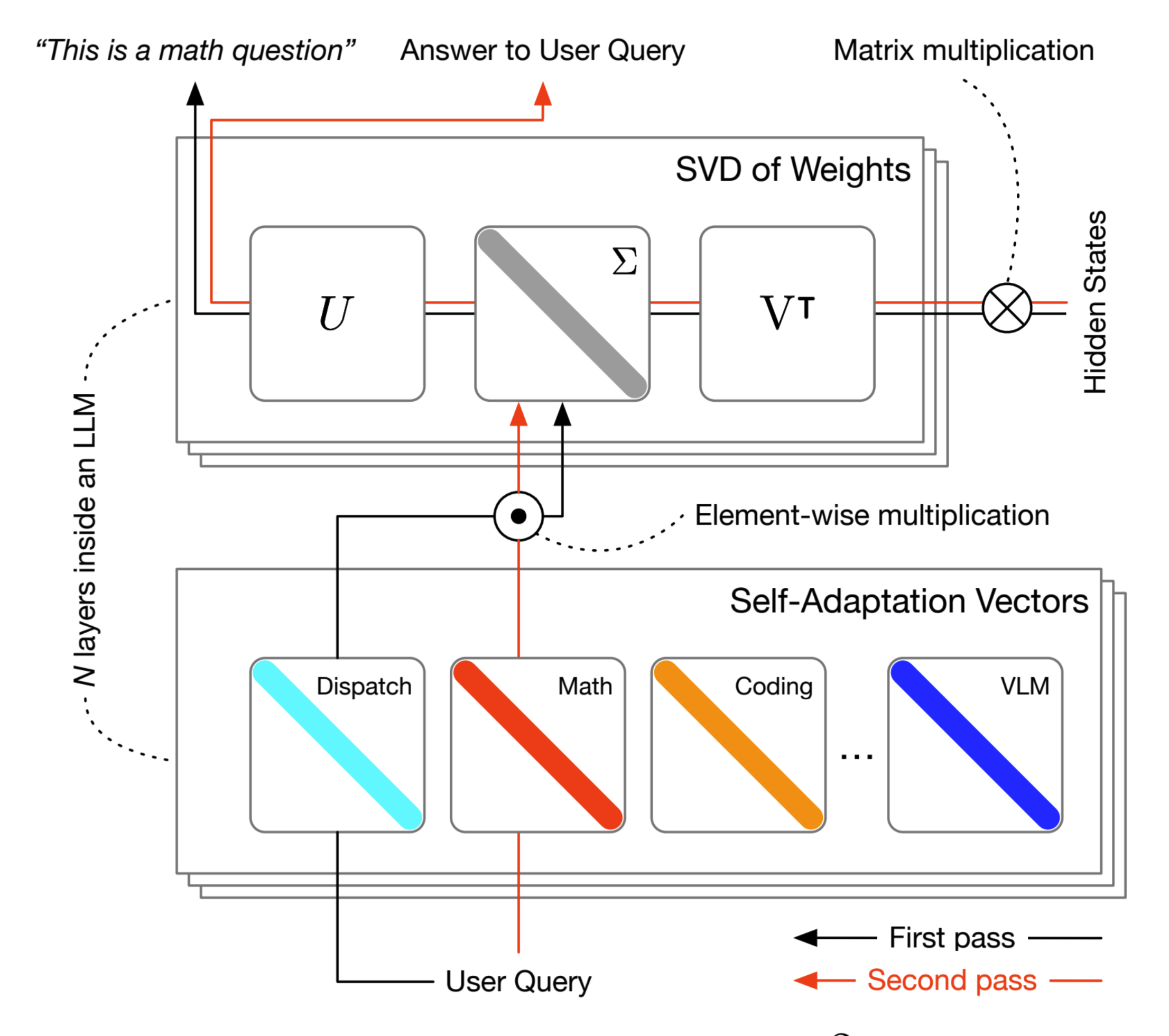
From references 2 – Overview of Transformer²
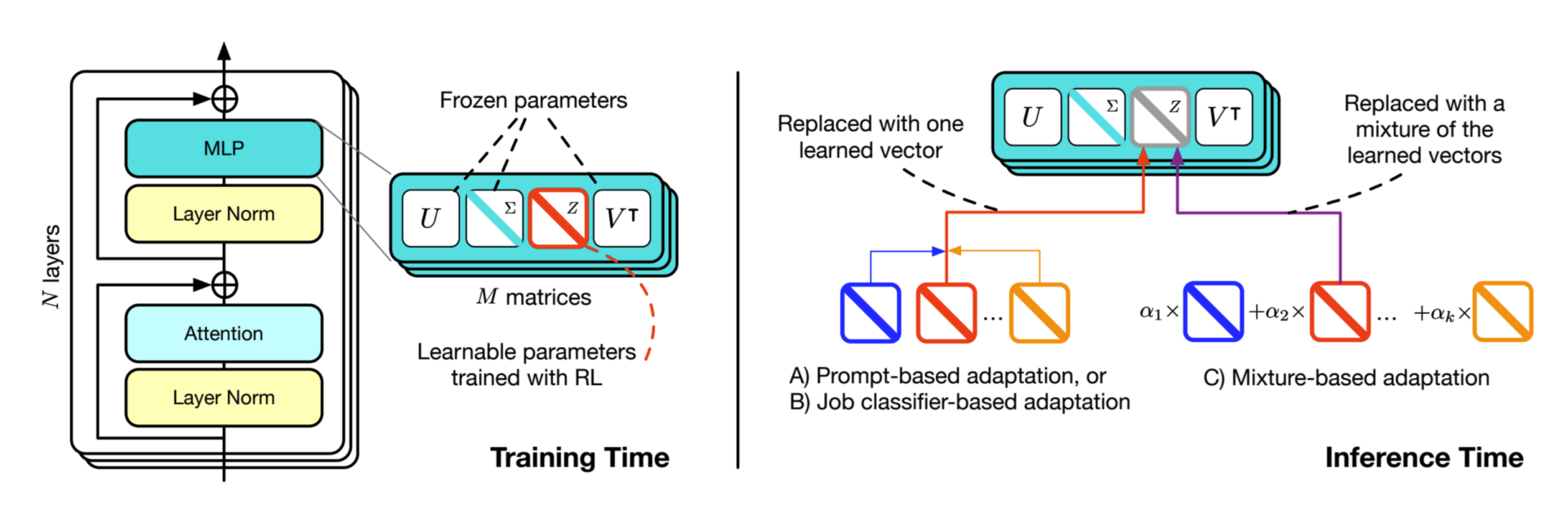
The Transformer² model architecture revolves around the novel Singular Value Fine-Tuning (SVF) mechanism, which efficiently adapts LLMs by modifying the singular values of their weight matrices. This approach involves training lightweight, task-specific “expert vectors” that scale the singular components of these matrices, enabling targeted adaptation while preserving the latent knowledge within the pre-trained weights. Transformer² employs a two-pass mechanism at inference:
- Task Identification: Determines the task-specific requirements.
- Expert Vector Adjustment: Dynamically modifies model behaviour using pre-trained expert vectors.
(Like a worker using different toolkits for different tasks.)
This architecture supports three adaptation strategies: prompt-based, classifier-based, and mixture-based. These strategies offer flexibility in selecting or combining expert vectors for different tasks. The model achieves real-time adaptation with minimal computational overhead by focusing on compact and compositional modifications through SVF, making it a scalable and versatile framework for dynamic LLMs.
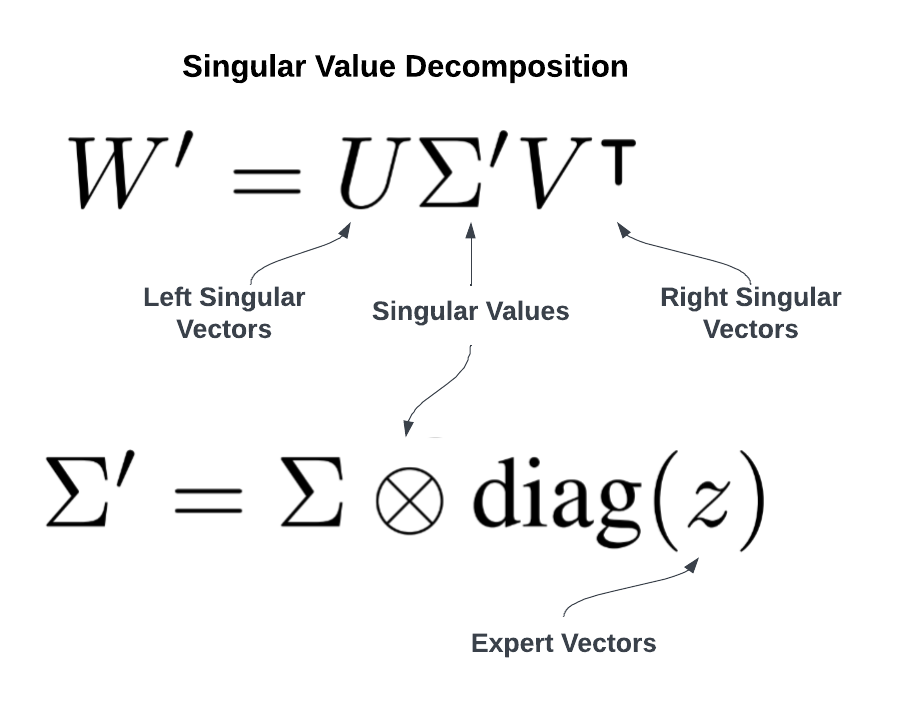
Inspired by references 2 – SVD formula
At the heart of Transformer² is SVF, a parameter-efficient method that enables the model to specialize in specific tasks dynamically. Transformer² decomposes its weight matrices during training using Singular Value Decomposition (SVD). This process identifies and tunes only the critical components (singular values) most relevant to a given task, leaving the rest of the model unchanged. SVF reduces the computational overhead of traditional fine-tuning methods, such as LoRA, while achieving higher task-specific performance.
From references 2 – Transformer² Method Overview
From references 2 – Transformer² Method Overview
One of the most powerful features of Transformer² is its ability to reuse pre-trained z-vectors, which serve as modular, task-specific components. Each z-vector is designed to specialize in a particular skill or domain and can be dynamically combined with others to address more complex tasks. These expert vectors are compact, highly efficient modifications trained via reinforcement learning to adjust the singular values of the LLM’s weight matrices. The model maintains its latent knowledge by leveraging this targeted fine-tuning approach while adapting flexibly to diverse tasks. The modularity of these z-vectors ensures seamless integration and reusability across different models and applications, establishing them as a foundational element of the Transformer² architecture.
This architecture supports three adaptation strategies to enable flexible and efficient task-specific modifications.

From references 2 – Prompt-based adaptation example
Prompt Engineering
- Prompt-based adaptation is the simplest adaptation method. An adaptation prompt is constructed to ask the model to categorize the input task.
- Based on the model’s response, one of the pre-trained expert vectors z′ corresponding to the identified domain or skill is selected from the available set z.
- If the task does not match any of the pre-trained experts, the model falls back to its base weights by using a generic others category. This approach is lightweight and leverages the base LLM’s inherent reasoning capabilities.
Classification Expert
- This method builds upon prompt engineering by introducing a task-specific classifier trained to identify the input task.
- Using the SVF framework, the base LLM is fine-tuned on a dataset of task examples to create a specialized classification expert.
- During the first inference pass, this classification expert improves the model’s ability to select the most appropriate z′ vector for handling the input prompt, enhancing task identification accuracy.
Few-Shot Adaptation
- Inspired by few-shot learning techniques, this approach assumes access to additional task-specific examples (few-shot prompts) during inference.
- The method creates a new expert vector z′ by linearly interpolating between the pre-trained expert vectors z, weighted by coefficients optimized using the Cross-Entropy Method (CEM).
- The optimization process evaluates potential combinations of expert vectors based on performance on the few-shot prompts. This strategy avoids extending question prompt lengths and only requires optimization once per target task, making it suitable for complex or unseen scenarios.
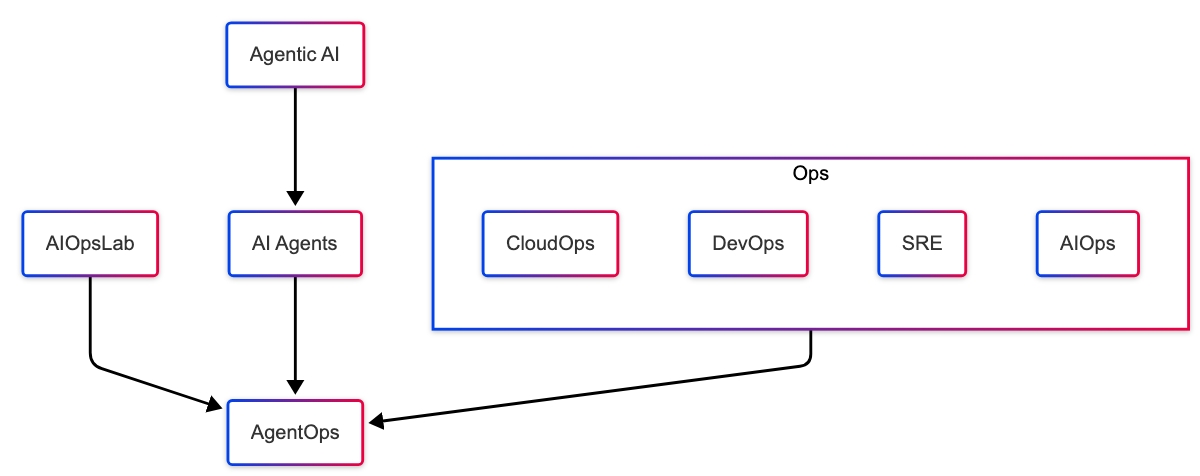
Synergy Between Titans and Transformer²: Agentic AI in DevOps and Kubernetes

Like Neo instantly learns Kung Fu, Titans can store persistent DevOps knowledge, best practices, deployment strategies, and security policies. At the same time, Transformer² dynamically adapts these skills to new environments, evolving infrastructures, and real-time incidents.
Titans and Transformer² represent two innovative and complementary approaches to advancing AI capabilities. While Titans excels at managing long-term and task-specific memory, Transformer² shines in its ability to adapt to tasks in real time dynamically. Together, they enhance the efficiency and adaptability of AI systems and set the foundation for Agentic AI, intelligent systems that act autonomously, make context-aware decisions, and execute tasks with minimal human intervention. In the context of DevOps and Kubernetes, these agentic systems have the potential to revolutionize workflows by proactively managing infrastructure, troubleshooting, and optimizing operations.
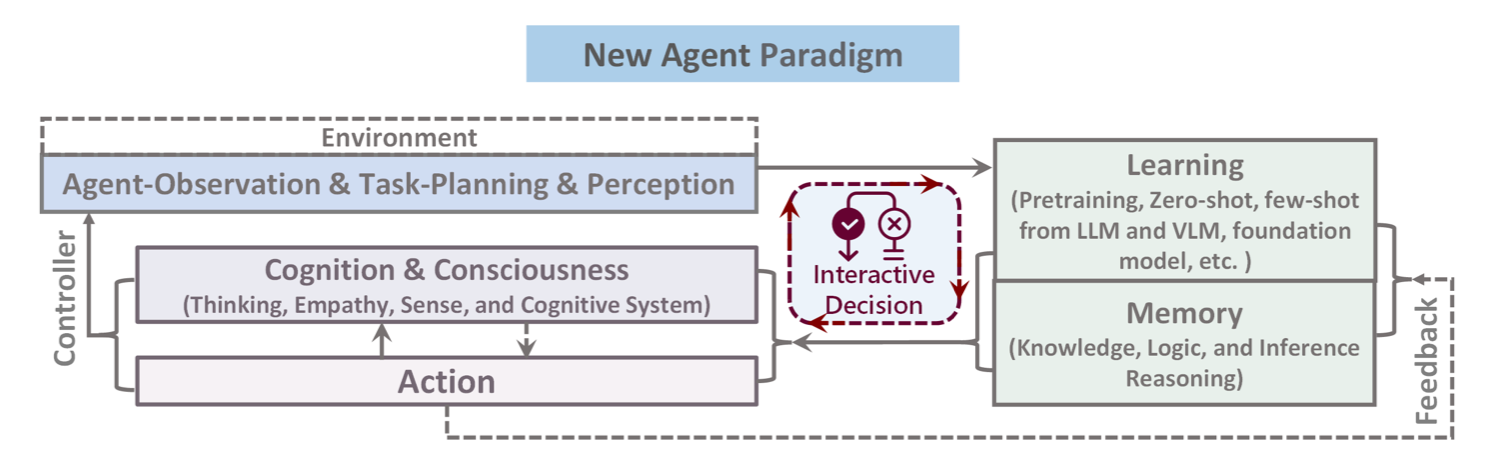
From references 7 – Agent Paradigm
The evolution of Agentic AI is deeply tied to advancements in LLM architectures, where models like Titans and Transformer² enhance the capabilities of AI agents beyond static task execution. The agent paradigm defines AI agents as systems capable of perceiving, reasoning, acting, and learning within dynamic environments. In the DevOps and Kubernetes space, AI agents must not only retrieve and process information but also make real-time decisions, automate workflows, and continuously improve their operations.
Titans and Transformer² work synergistically within this paradigm by addressing complementary aspects of intelligence. Titans provide persistent memory, ensuring AI agents retain long-term knowledge of Kubernetes best practices, CI/CD pipelines, and infrastructure patterns. This persistent memory acts as the agent’s knowledge base, reducing reliance on external queries and allowing for deeper contextual understanding. Meanwhile, Transformer² enhances real-time adaptability, dynamically fine-tuning the agent’s responses based on live system conditions. This ensures that when an agent detects an anomaly, such as a sudden surge in traffic, it can query historical patterns (Titans) while fine-tuning a response based on the latest telemetry data (Transformer²).
This synergy enables self-healing Kubernetes clusters, proactive incident resolution, and intelligent workload orchestration in practical applications. AI agents can autonomously detect, diagnose, and mitigate infrastructure failures, leveraging Titans to recall past incidents and Transformer² to adapt to unseen edge cases. Moreover, by integrating tool execution with LLM-powered reasoning, agents can analyze data and take corrective action, such as adjusting resource allocation, modifying Helm configurations, or restarting failing pods.
As DevOps environments continue to evolve, Agentic AI powered by Titans and Transformer² represents the future of autonomous cloud operations. These models enable AI agents to become more self-sufficient, proactive, and capable of managing complex workflows without human intervention. The next step in this evolution is to refine AI’s ability to continuously learn from operational feedback, ensuring that each deployment, failure, and success refines the agent’s expertise. This will make AI-driven automation more adaptive, efficient, and effective over time.
Agentic AI is just the beginning. As Titans and Transformer² refine their ability to manage infrastructure autonomously, the same principles could be applied to finance, logistics, and even healthcare. Imagine AI systems that optimize cloud resources and autonomously manage cybersecurity defences, fine-tune supply chain logistics in real-time, or even personalize medical treatments based on evolving patient data. The ability to think, remember, and adapt will define the next generation of truly intelligent systems.
Conclusion
The evolution of LLMs has reached a pivotal moment with the introduction of architectures that go beyond traditional Transformers. Titans and Transformer² represent two distinct yet complementary advancements, addressing the key limitations of Transformers: memory persistence and real-time adaptability.
Titans introduce a neural long-term memory that allows models to retain and retrieve contextual information beyond fixed windows, overcoming the quadratic complexity constraints of self-attention. By integrating short-term, contextual (long-term), and persistent memory, Titans offer superior performance in long-context modelling, time series analysis, and retrieval-intensive tasks.
Transformer² redefines adaptability by implementing a self-adaptive framework, dynamically fine-tuning model weights at test time. This allows LLMs to adjust to task-specific nuances without requiring extensive retraining, significantly reducing computational costs while enhancing efficiency in diverse domains like coding, mathematics, and multi-modal reasoning.
The future is Agentic!
References
- Attention Is All You Need – Google Research
- Transformer²: Self-Adaptive LLMs – Sakana AI
- Titans: Learning to Memorize at Test Time – Google Research
- An Interactive Agent Foundation Model? – Medium
- A Mathematical Framework for Transformer Circuits – Anthropic
- Recurrent Neural Network – Wikipedia
- An Interactive Agent Foundation Model – Microsoft